PROBLEM LINK:
Author: Jingbo Shang
Tester: Kevin Atienza
Editorialist: Kevin Atienza
DIFFICULTY:
Hard
PREREQUISITES:
Square root of a graph
PROBLEM:
Define the augmentation of a tree as the graph formed by joining any pair of nodes within distance two with an edge.
Given a graph with N nodes and M edges, output a tree whose augmentation is the given graph. If there are multiple possible solutions, output any of them.
QUICK EXPLANATION:
Handle the case N \le 2 separately.
If you know two edges that share a common node that belongs to the original tree, you can construct the rest of the original tree in O(M) time (or O(N \log N + M) time) by growing the tree (i.e. adding nodes one by one), or determine that the two edges do not actually belong to the original tree.
To find two edges sharing a common node, we use the following procedure:
- First, find a triangle (a 3-clique) containing 1, say (1, b, c). This can be done in O(M) time. Next, try assuming that two of the three edges in the triangle belong to the original tree, and construct the tree. There are only three possibilities to try. Always check if the augmentation of each tree you get is the input graph, and if you find one that works, output it.
- If none works, then we know that none of the edges in the triangle are actually in the original tree, but there must be a node “d” that are adjacent to 1, b and c in the original tree. Our goal now is to find this d. Let’s call this the center.
- First, find the largest clique of nodes containing 1, b and c. This can be done in O(M) time. It is always the case that the center is adjacent to all nodes in the clique in the original tree.
- Next, for each node I in this clique, compute the nodes adjacent to I but doesn’t belong in the clique. Call this \text{outside}(I). All the \text{outside}(I) can be computed in O(M) time.
- If \text{outside}(I) is empty, then I must be a leaf on the original tree. Otherwise, it must be a non-leaf. (Assuming the original tree wasn’t a star graph, which is impossible at this point.)
- Also, it’s clear that the center is a non-leaf.
- Also, if two non-leaves have $\text{outside}$s that intersect, then one of them must be the center.
- Let I_1, I_2, \ldots I_k be the non-leaves. For each of the following pairs of non-leaves (J, K): (I_1, I_2), (I_2, I_3), (I_3, I_4), \ldots, (I_{k-1}, I_k), (I_k, I_1), check whether \text{outside}(J) and \text{outside}(K) intersect. If it does, then try J or K as center. Surely one will work.
EXPLANATION:
There are many solutions for this problem. Here we’ll describe just one possible solution. If you have a different solution, feel free to describe it in the comments!
For ease of discussion, we’ll define some terms here. We’ll call the input graph the augmented graph, and the output tree the original tree. We’ll call an edge a true edge if it is also an edge in the original tree, and a false edge otherwise. Thus, among the M edges in the augmented graph, there are N - 1 true edges, and the remaining ones are false. We’ll also call two nodes adjacent if they are adjacent in the augmented graph.
A trivial, but very important, observation we will keep on using is the following:
Observation 0: The N-1 true edges form a tree by themselves.
Also, in the following, we assume N \ge 3, because the cases N < 3 are trivial: there is only one tree with N = 1, and N = 2.
Making the problem easier
The current problem seems intractable, because we seem to have nowhere to start finding true edges. So let’s make the problem easier for now: let’s assume that we know at least one true edge, say (a,b).
Knowing one true edge
Will this help us? We don’t know yet, but at least we now have a starting point. It makes sense to try to find another true edge adjacent to this edge. Consider a true edge adjacent to (a,b), say (b,c). Then there must be a false edge (a,c), because they are of distance 2 in the original tree. Conversely, if (a,c) is a true edge, then (b,c) must be a false edge. Thus, we have acquired our first piece of information:
Observation 1: If (a,b) is a true edge, then any node c adjacent to either a or b by a true edge must be adjacent to both in the augmented graph.
Is the converse true? Namely, if c is adjacent to both a and b in the augmented graph, then is one of these edges true? Well, let’s suppose for the purpose of contradiction that both of these edges are false. Then c is of distance two from a and from b, which means that there is some node a' midway between a and c, and some node b' midway between b and c. But it’s possible that a' = b', so let’s consider these cases:
- If a' = b', then (b,b'), (a',a), (a,b) constitutes a triangle of true edges, which is impossible since the true edges form a tree.
- If a' \not= b', then (b,b'), (b',c), (c,a'), (a',a), (a,b) consitutes a cycle consisting of true edges, which is again impossible because true edges form a tree.
So we have just shown that it’s impossible for both edges (a,c) and (b,c) to be false. Thus, at least one must be true and we have just proven the converse!
Observation 2: If (a,b) is a true edge, then any node c adjacent to both a and b in the augmented graph must be adjacent to either a or b by a true edge.
This is great, because we might be able to extend our set of known true edges now: Just find a node c adjacent to a and b. Then either (a,c) or (b,c) must be a true edge. We know we can always find such a node c because we know the set of true edges are connected to each other, thus one of them must be adjacent to a or b. Unfortunately, we still don’t know which one of (a,c) or (b,c) is the true true edge. Well, let’s ignore that problem for now and assume that we know which one it is. Let’s say it’s (b,c).
Knowing two true edges
Now let’s assume that we know for sure that (a,b) and (b,c) are true edges. What do we do next?
Let’s again try to find another true edge adjacent to either a, b or c. In this case, we still have a problem, because we don’t know which node among these three have another true edge adjacent to it. It may very well be the case that only one of these nodes are adjacent to some other true edge. Let’s consider these cases separately.
First, assume there is some true edge (c,d) containing c. Then there must be a false edge (b,d) because they are of distance two in the original tree. However, there must be no edge (a,d) (in the augmented graph), because they are of distance three. The case is very similar for the true edge (a,d): (b,d) must be a false edge and (c,d) must not be an edge.
Finally, if there is some true edge (b,d), then (a,d) and (c,d) must be false edges, because they are each of distance two.
This is great, because this means that we can identify which node d is adjacent to with a true edge, assuming it’s adjacent to either a, b or c:
- If d is adjacent to a and b, then (a,d) is a true edge.
- If d is adjacent to a, b and c, then (b,d) is a true edge.
- If d is adjacent to b and c, then (c,d) is a true edge.
This means that given the true edges (a,b) and (b,c), we can find another true edge! And of course, as before, we can always find such a d, because the true edges are all connected to each other.
Can we keep going? Yes! Just find another node adjacent to at least two nodes already in our growing tree, and with very similar arguments, we can always uniquely identify which node it is adjacent to with a true edge. In fact, we can continue doing this until we build the whole tree!
But how do we know if some node, say x, is adjacent with a true edge to our growing tree, say T? Well, in the case where we only know two true edges, x is always adjacent to at least two nodes in T. In fact the same is true when T is larger:
Observation 3: If T is a tree of true edges and x is adjacent to some node of T with a true edge, then x is adjacent to at least two nodes of T in the augmented graph.
This is true because if x is adjacent to some node y\in T with a true edge, and z is some neighbor of y in T, then (x,z) must be a false edge. Thus, x is adjacent to y and z in the augmented graph.
Using all of these observations, we can now form an algorithm to build the whole tree assuming we know at least two true edges (a,b) and (b,c):
- Initialize the tree T with just the true edges (a,b) and (b,c).
- While T doesn’t contain all N nodes, find some node x adjacent to at least two nodes in T. Based on which nodes x is adjacent to, determine (uniquely) which node it is adjacent to with a true edge, and add this edge (and node x) in T.
And in fact, with the right implementation, this can be turned into an O(M) algorithm (similar to topological sorting):
- For each node x, keep track of how many nodes of T it is adjacent to, let’s say \text{count}[x].
- Also, maintain a list of nodes x not yet in T but where \text{count}[x] is at least two.
- When you add new nodes to T, update the $\text{count}$s, and also append to the list every node x whose \text{count}[x] becomes 2.
This means that we can now write the following strong observation:
Observation 4: If we know at least two true edges (a,b) and (b,c), then we can recover the original tree in O(M) time.
We can in fact strengthen it a little more, in two ways.
First, suppose we don’t know whether (a,b) and (b,c) are actually true edges, and we want to know if they are or not. Well, we can try running our algorithm on (a,b) and (b,c). Now, it’s possible that we don’t end up with a tree, in which case we know that (a,b) and (b,c) are not simultaneously true edges. Otherwise, if we end up with some tree, it might still be the case that this is not a valid original tree. In this case, we can simply check whether the tree is valid by augmenting it and checking whether the result is equal to the input graph. If so, then we know that (a,b) and (b,c) are actually true edges (and we have an answer to our problem). Otherwise, they are not.
(Note though that if the algorithm fails, then we only know that (a,b) and (b,c) are not true edges simultaneously, i.e. (a,b) or (b,c) can still be true edges, though they can’t be both at the same time.)
The reason this works is that if (a,b) and (b,c) are indeed true edges, then the algorithm should return a valid tree by the correctness of our algorithm. Otherwise, we don’t have this guarantee, but in fact we’re sure that whatever tree it outputs can’t be valid, because by assumption (a,b) and (b,c) can’t be both true edges simultaneously.
Observation 5: Given two edges (a,b) and (b,c), we can recover the original tree in O(M) time if (a,b) and (b,c) are simultaenously true, or determine that they can’t be both true at the same time.
We can strengthen this even more. If we know only one true edge (a,b), then using Observation 2, if we find a node c adjacent to a and b in the augmented graph, we know either (a,c) or (b,c) is a true edge. Since there are only two possibilities, we can try both possibilities and run our (strengthened) algorithm above on them, and surely we’ll end up with a valid tree from one of the trials. What’s more, such a c always exists because the true edges form a tree. Thus, as long as we know at least one true edge, we can already construct the whole tree. Note that this runs in O(M) time!
Observation 6: Given an edge (a,b), we can recover the original tree in O(M) time if (a,b) is true, or determine that (a,b) is not true.
What remains is to find at least one true edge.
Finding one true edge
Now, let’s discuss how to find a true edge. Let’s start at the following statement: In a triangle of nodes, if at least one edge is true, then we can construct the whole tree. This is just a combination of Observations 2 and 4. Thus, it makes sense to start looking at some triangle of nodes.
We can find a triangle of nodes \{a, b, c\} in O(NM) time, but we can in fact do better with the following observation:
Observation 7: Every node belongs to some triangle.
That this is true can be seen as follows:
- Consider some node x. Obviously it adjacent to some other node y by a true edge.
- Now, either x or y is adjacent to some other node z by a true edge. First, assume (y,z) is a true edge. Then (x,z) is a false edge because their distance is 2, which means that \{x,y,z\} is a triangle. The same is true when we assume (x,z) is a true edge.
- Thus, x belongs to some triangle of nodes.
Using this observation, we can simply find a triangle containing some fixed node, say 1, in O(M) time.
Now we have a triangle \{a, b, c\}. First we check whether one of (a,b), (b,c) or (c,a) is true (using our algorithm above three times). If one of them works, then we already have the original tree and we are done!
The remaining case is when all of (a,b), (b,c) and (c,a) are false edges. In this case, they are all of distance two from each other in the original tree, and thus there may be some intermediate nodes (or just one intermediate node) between them. Let’s examine all possibilities:
- There may only be one intermediate node, say x, with (a,x), (b,x) and (c,x) being true edges.
- There may be at least two intermediate nodes, say x and y. Without loss of generality, assume x is intermediate to (a,b) and y is intermediate to (b,c). Since a and c are distance two away from each other, there must be an intermediate node between them. Now, (i) it can’t be x or y because it would generate some cycle of true edges (of length 4). But (ii) it can’t also be another node z because that would also give a cycle of true edges (of length 6). Thus, this case is impossible!
The following illustrates the latter case more clearly:
(i)
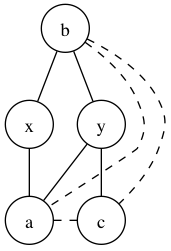
(ii)
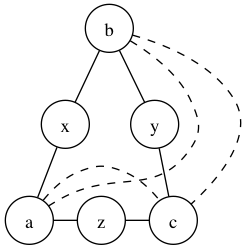
Here, true edges are represented as solid lines, and false edges as dashed lines. Note that in both cases, there is always a cycle of true edges.
This means that there is only one possibility: That there is only one intermediate node, say x, with (a,x), (b,x) and (c,x) being true edges. Let’s call this node x the center of \{a, b, c\}. Node that finding x means finding at least one true edge (indeed three), so our new goal would be to find the center x given \{a, b, c\}.
Finding the center
Let’s get some candidates for the center. Let’s define a candidate center as a node that is adjacent to all nodes \{a, b, c\} (in the augmented graph). Clearly this is the minimum requirement for a node to be a center, though it’s not enough. The problem is, there could be many such nodes. (In fact, it could be all other nodes!) But there is a useful observation about these candidates:
Observation 8: All candidate centers form a clique together with \{a, b, c\}, and in the original tree they form a star graph with the “center” (defined earlier) as the center node.
Why is this true? We can look at it this way. We already know that \{a, b, c\} together with the real center x already form a clique, and the original tree is a star graph with x as the center node. Now, suppose there is another candidate center d, so the edges (a,d), (b,d) and (c,d) exist (and we want to show that d is adjacent to x). Assume one of these edges are true; without loss of generality assume (a,d) is true. This means that the sequence (d,a), (a,x) and (x,b) is a sequence of true edges and thus the distance between d and b is three. But the distance must be at most two because (b,d) is an edge! Thus, it’s impossible for (a,d) to be true (and by symmetry, (b,d) and (c,d) too). Thus, (a,d), (b,d) and (c,d) are all false. In particular, \{ a, b, d\} constitutes a triangle of false edges, and by the argument above, we know that there must be a unique intermediate node for this triangle. But we already know that x is the intermediate node for (a,b), which means that x must be intermediate for (a,d) as well. Thus, d must be adjacent to x with a true edge.
The following image illustrates what it really looks like.
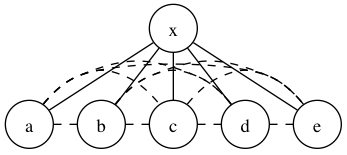
Considering only true edges (solid lines), the nodes form a star graph with x as center. Including false edges (dashed lines), they form a clique.
Now, among all candidates, how do we know which one is the center? Since they form a clique, of course we can only determine it using nodes outside of the clique. What can we say about nodes outside the clique in relation to nodes inside? For each node i in the clique of candidate centers, we can define \text{outside}(i) as the set of nodes adjacent to i that is outside the clique. In terms of the original tree, the following illustrates \text{outside}(i) for various nodes i (the bolded nodes are the candidate centers):
(\text{outside} of a center)
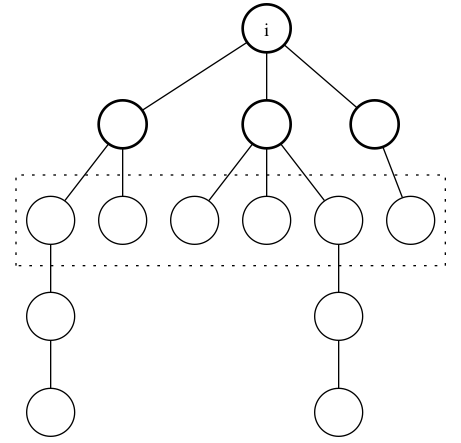
(\text{outside} of a non-center)
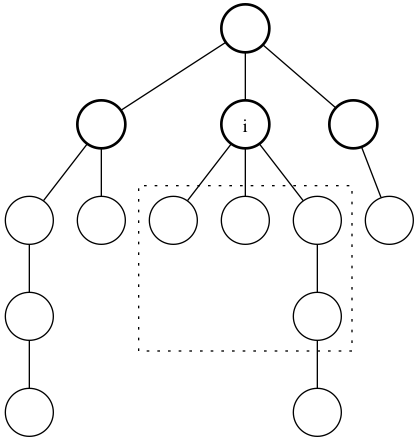
Some interestings can be observed. First, we can classify candidate centers into two: whether they are leaves or non-leaves in the original tree. This distinction is useful because we know that the center isn’t a leaf in the original tree.
Leaves can easily be identified using \text{outside}(i): Node i is a leaf if and only if \text{outside}(i) is empty. Well, this works except for one kind of tree: the star graph. In a star graph, all $\text{outside}$s are empty even though the center is not a leaf. But actually, if the original tree is a star, then the augmented graph must be the complete graph, and in fact any star tree on the same set of nodes augments to a complete graph, regardless of which node is used as center! Thus, in this case, any edge could be true (though of course not all at the same time), and we would have acquired a true edge during the first steps of our algorithm (i.e. find a triangle and test each edge). Thus, a complete graph wouldn’t have reached this point of the algorithm and we can simply ignore this case!
Thus, assuming the graph is not complete, we can safely ignore all leaves because we know none of them is the center. This could cut down our candidates, but the problem is, there could still be many non-leaves.
What else can we know about the center? Here’s the key observation:
Observation 9: Given two non-leaves x and y, if \text{outside}(x) and \text{outside}(y) intersect, then either x or y must be the center.
This is evident from the following image:
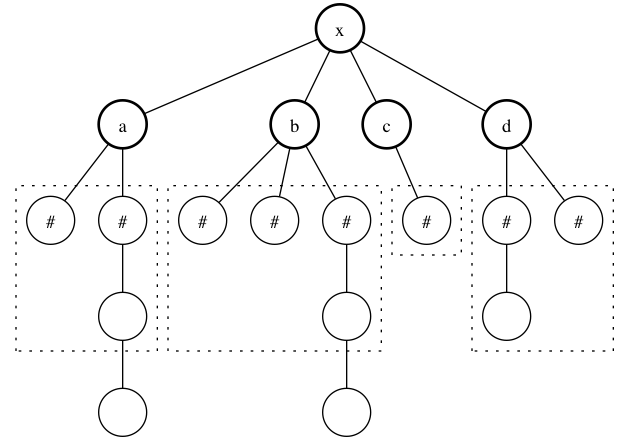
The dotted boxes are the $\text{outside}$s of the nodes a, b, c and d, while nodes marked with # belong to \text{outside}(x).
Notice that if you take two non-center non-leaves, then they are already of distance two from each other, which far enough away for their $\text{outside}s to not intersect. On the other hand, the center's \text{outside} always shares at least one node with the \text{outside}$ of any other node.
Thus, if we find two nodes with intersecting $\text{outside}$s, then we are left with just two candidates for the center, which is good enough for our purposes since it leaves us with just a fixed amount of calls to our algorithm! (Leaving us with an O(M) time algorithm)
But how do we find such a pair? Here’s one possible way: Let i_1, i_2 \ldots i_k be the non-leaves, ordered arbitrarily. Then, for each of the following pairs of nodes:
Check whether their $\text{outside}$s intersect. If they do, then we have found the pair we want!
This works because the center belongs to this sequence, and since its \text{outside} intersects with any other node’s, surely it intersects with the \text{outside} of its neighboring node in the sequence.
How fast does this run? Checking intersection of sets requires time linear to the sizes of the $\text{outside}s, but since each \text{outside} is only traversed at most twice, the running time is linear in the total size of all \text{outside}s. To get the total size, note that the \text{outside}$s of non-centers don’t intersect, so their total size must be at most N. Also, the \text{outside} of the lone center is definitely at most N. This means that the total size of the sets is at most 2N = O(N), and this algorithm runs in O(N) time!
In the literature
Things like the augmented graph and the original tree actually have more common names in the literature.
We define the n th power of a graph G, denoted G^n, as the graph on the same vertex set such that there is an edge between two vertices if and only if their distance on G is at most n. Using this definition, we say that the augmented graph is the square of the original tree, and the original tree is a square root of the original graph.
It’s been shown that computing a square root of a square graph, or even determining whether a graph is a square, is NP-hard. On the other hand, computing a tree square root of a graph can be done in linear time as we have just shown. This paper shows another linear time algorithm to do the same thing, and also discusses many more interesting things about graph powers.
Time Complexity:
O(N \log N + M) or O(M)